国产大模型离ChatGPT还有多远?
国产大模型离ChatGPT还有多远?
自CHATGPT问世已经过去了半年时间,国内大厂们已经纷纷入局,国产ChatGPT产品争相面世。但目前为止,相关产品几乎都是在弱人工智能的基础上演化而来,离强人工智能尚有距离。为什么“学习能力”一向很强的国内厂商,这一次没有快速追赶上ChatGPT呢?
2022年11月,OpenAI的一记“惊雷”点燃了国内外巨头的竞争欲。
经过几个月的“角逐”,国内第一批ChatGPT产品已经面世。但是,不管是打响国内ChatGPT第一枪的百度“文心一言”,还是三六零(行情601360,诊股)、阿里以及科大讯飞(行情002230,诊股)紧急孵化的各个大模型,似乎都有些“雷声大雨点小”的意味。
要知道,ChatGPT的爆火,是因为其表现出了近乎于人类的语言表达能力、超强的学习能力以及语义理解能力,不仅能够通过微软的工程师测试,还能够撰写学术期刊论文等等。但这些,似乎都没有在任意一款国产ChatGPT产品上体现……
为什么国产大模型,这一次没有追上ChatGPT?
现实差距
国内的AI机器人(行情300024,诊股)、AI识图技术已然“炉火纯青”,相关产品也曾一度风靡海外。
然以AI机器人、AI识图以及视频识别技术等一系列专用人工智能,统称为弱人工智能,这些弱人工智能产品能够回答简单的问题,完成系统预设好的指令,并与其他家电产品联网,营造智能家居系统。
相对于弱人工智能,ChatGPT代表的是一种强人工智能,用户只要对其发出比较具体的提示语,对其提出相关要求,ChatGPT就可以写程序、做翻译、写论文、参加考试甚至进行文化创作,最重要的是,还能“胡说八道”。
“胡说八道是只有人类才能产生的行为”,三六零创始人周鸿祎曾经如是评价过。强人工智能能够覆盖弱人工智能的所有功能,还能够完成弱人工智能所不能完成的任务。
也就是说,ChatGPT的诞生,完全可以倾覆弱人工智能的全部成果。因此,ChatGPT才会引起全球科技巨头的警觉。
而当下国产ChatGPT产品形成于“临时抱佛脚”,带有很重的弱人工智能“影子”。
由此可见,从弱人工智能到强人工智能并不是一次简单的“复制粘贴”,而是一次重大的科技飞跃,甚至可以被评价为时代变迁的开端。
体系互异
一个从大环境角度出发的答案,是两国的创新机制不同。
具体而言,ChatGPT是典型的硅谷式创新产物。清华大学公共管理学教授梁正表示,这个创新生态体系有几个关键的步骤,首先要有创新性的机制,一些企业聚集了一批理想主义的技术天才,走了一条不寻常的道路,最后再由大公司进行投入和资源整合,完成商业化。
在这个过程中,隐藏着三个体系:一是研究型大学,有一批科学家在做探索性的工作;二是使命导向的实验室体系,以国家的使命驱动前沿研究;三是硅谷,基于创新创业和风险投资的商业生态。这三者相互叠加,密切联动,先从0-1突破,在通过大公司注资完成从1-2的工作,从而形成从科研到产业化的良性循环。
ChatGPT的诞生,就是微软重金投资了一家看起来非同寻常的公司——OpenAI,这家公司曾经无产品、无体系,但有一个技术天才,完成了一个又一个的构想,还受到了大资金的青睐,十年后,ChatGPT轰动了全球。
而国内的创新体系大致为,高等学府中的科学家做探索性的工作-这些科学家被高薪聘请到大公司-最后以大公司为背景,对这些探索性研究成果进行投入和落地。
这种体系很稳,且我国在人工智能方面的研究看似也从未停歇。早在2018年,中国人工智能方面的论文在总量和被引论文数量上就排在了世界第一,专利数量排名第二,中国人工智能企业数量位列世界第二,中国人工智能领域的投融资占到了全球的60%,成为全球最“吸金”的国家。
然而,尽管我国人工智能相关论文数量已经形成了一定的规模,论文被引用的次数也颇多,但距离真正的成果还有一定的距离。
不单是研发差距,风投的投资思维差异也是影响创新积极性的因素之一。国内的风投思维仍是“不投没谱的事情”,根据梁正教授的说法,巨头们可能不愿意做获利前景太远的事情,很少有人像微软一样,会押注一家“非盈利”的小公司。
一项倾覆世界的研发成果诞生,可能还需要很多个“临门一脚”才能完成。OpenAI为做出ChatGPT也耗费了大量的人力、物力、财力和时间成本。因此,国产大模型想要赶超ChatGPT,尚需时间。
语言殊途
除了环境因素,摆在国产大模型面前的还有现实因素。
相关学术论文显示,ChatGPT是融合了Transformer和强化学习两项技术。
拆分来看,所谓Transfoemer架构是一种基于注意力机制的神经网络架构,被广泛应用于自然语言处理领域。这一架构能使得ChatGPT能够通过分析输入的语料来理解人类语言的语法、语义,并按照语法生成流畅且拥有较强理解力的应答。
在此基础之上,ChatGPT使用的强化学习技术,通过外界设定的奖惩规则,自主学习,最终在某项具体任务中达到甚至超越人类的表现。
强化学习模型最知名的应用就是DeepMind团队开发的围棋机器人AlphaGo,其在2017年打败了人类最顶尖的骑手柯洁。DeepMind团队还开发出另一项颠覆性的研究——AlphaFold数据库,在蛋白质结构预测上远远超越人类,并在2022年宣布预测出地球上几乎所有的蛋白质结构。
简言之,就是ChatGPT需要先理解人类的语法、语义,再通过收集大量资料、不停完成训练、反复学习才能够达到当前类似于人类,甚至超越人类的表现。
而国产ChatGPT在这两项技术方面都略逊一筹,一方面是数据库容量,而更重要的是中、英两种语言结构的天然差异。
当前的ChatGPT是基于英文的,英文能够让ChatGPT通过词缀、词性、标点符号等,更加方便的将相同词缀的词汇构成并列。如以ing结尾的词汇,可以被ChatGPT快速并列为进行时态的词汇。而中文的正在进行时表达则相对多元。
另外,英文句子的结构是网状的,理论上,在语法正确的情况下,一句英文可以由一万个词汇组成,一个句子中能够有N个谓语、非谓语、从句等等。
反观中文,一些词汇能当动词也能当名词,一个词汇的褒贬含义还需要结合上下文理解,标点符号代表的含义也多有不同,学习起来并不容易。
除此之外,强人工智能代表的是人类知识的集大成者,而大多顶尖的学术类论文、文献、资料等都是英文。这也意味着ChatGPT的学习知识库远比国内的大模型要丰富,
芯片掣肘
先天条件遇到门槛,硬实力还遭遇了“卡脖子”。
据了解,ChatGPT的训练过程需要耗费大量的计算资源和时间,这需要企业具备强大的计算能力和相应的设备。
资料显示,ChatGPT的总算力消耗约为3640PF-days(即假如每秒计算一千万亿次,需要计算3640天),需要7至8个投资规模30亿、算力500P的数据中心才能支撑运行。
支撑这些算力的,就是英伟达研发的全球顶尖的A100和H100智能芯片。有声音认为,即便是部署1万块英伟达A100显卡,也要持续不间断运算10年才能达到当前ChatGPT这样的算力高度。
但目前,这两款芯片在全球具有不可替代性,而英伟达A100和H100已经被限制出口中国。
为了继续占领中国市场,英伟达已经针对中国推出了中国特供版A800,但这两款芯片存在明显的性能差距。H100芯片的中国特供版也即将研发完毕,很快就能在中国上市。但芯片上的差距总是牵一发而动全身,单个芯片功能不足造成的时间差将导致国内AI花费更多的时间解析同样的数据。
有了芯片,还需要带动芯片的超级计算机。2020年,微软购买了28.5万个CPU和1万个GPU,联合OpenAI打造了一台AI超级计算机。根据2022年的全球超级计算机排名显示,这台超级计算机位列全球前五名。
虽然,我国的神威·太湖之光、天河-2A超级计算机也挤进了前十名,但有关分析显示,这两款超级计算机主要是用来做科研的,几乎不可能用来给科技公司做AI大模型的训练。
或许当前国内的大模型还处于微创新阶段,谈赶超ChatGPT为时尚早,但在巨头们的百舸争流下,有望形成两强格局。

-
鼓楼中国人寿携手光大银行华林分行推出“欢乐元宵·兔年元宵·祝福”客户联谊活动
2024-05-09
-
证监会对黄有龙赵薇孔德永分别采取5年证券市场禁入措施
2024-05-09
-
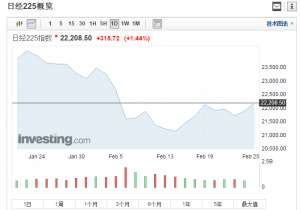
日韩股市周一双双高开 日经225指数涨幅扩大至1.44%
2024-05-09

-
量学扛鼎之作《股市天经:量波逮涨停》横空出世
2024-05-09

-
B站周三纳斯达克挂牌 一路下跌至2.26% 市值约31亿美元
2024-05-09
-
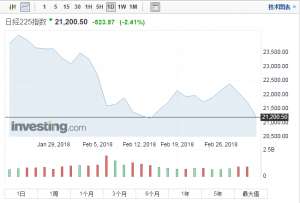
亚太股市继续走低,日本股市早盘大跌2% 东证股价指数开盘下跌1.65%
2024-05-09